DFT IPのsnapshot版を更新した。
固定小数版RTLのマージと、Cモデルを高速化版に更新した。
http://www.hi-ho.ne.jp/bravo-fpga/index.html
2013年1月25日金曜日
2013年1月21日月曜日
DFT IPの作成 19
固定小数版の小数部bit数だが、あれこれ試行錯誤するのが面倒くさくなってきたので整数部と合わせて32bitになるように20bitにした。ただ、その結果乗算部を1クロックで実行させることができなくなったので、以下のようにパイプライン乗算器を作成した。

乗算は、アキュムレーションRAMからくる値と円弧(sin/cos)値との乗算を行う。前者が整数部12bit、小数部20bitの2の補数形式の32bit固定小数である。円弧値は符号bit+整数部1bit、小数部20bitの22bit固定小数とした。 2の補数形式のままで乗算を行うと符号拡張する必要があり、回路がデカくなってしまうため、絶対値に変換してから乗算するようにした。
乗算は y = a * bだが、 ここで、例えば a を ah と al に分割する。 a = ah * 2^n + al だ。
そうすると、y = (ah * 2^n + al) * b = ah * b * 2^n + al * b となるので、乗算がah * b と al * bに分割できる。このようにして1クロックで動作できる程度のビット幅になるように乗算を分割して実行し、その次のステージでこれらを加算する。また、入力が負数の場合、例えば入力 a が負数の場合 ~a + 1として正数に変換する必要があるが、この+1の加算も上記の加算ステージで行うようにした。
で、固定小数版が浮動小数版に対してどの位誤差があるかだが、以下のようなデータの処理結果で比較してみた。

全データの、RTLでの処理結果とCモデルの処理結果の差の二乗の平方根を合算後、データ数で除して平均誤差を計算した。以下がその結果で、fxp15は15bit版、fxp20が20bit版だ。

平均値でみると20bit版の誤差はそれなりに小さい値だが、最大値は1.8超となっている。ただし、これは単純に回路の値と期待値との差なので、規模感はこれでは判らない。母数(期待値)との比を見るべきなんだろう。

最大誤差の箇所を検索したところ上記の箇所が見つかり、比を計算したところ1.3%の誤差であることが判った。
これ以上bit数を増やしたくないので、う~ん、、、まっいっか。という感じだ。

乗算は、アキュムレーションRAMからくる値と円弧(sin/cos)値との乗算を行う。前者が整数部12bit、小数部20bitの2の補数形式の32bit固定小数である。円弧値は符号bit+整数部1bit、小数部20bitの22bit固定小数とした。 2の補数形式のままで乗算を行うと符号拡張する必要があり、回路がデカくなってしまうため、絶対値に変換してから乗算するようにした。
乗算は y = a * bだが、 ここで、例えば a を ah と al に分割する。 a = ah * 2^n + al だ。
そうすると、y = (ah * 2^n + al) * b = ah * b * 2^n + al * b となるので、乗算がah * b と al * bに分割できる。このようにして1クロックで動作できる程度のビット幅になるように乗算を分割して実行し、その次のステージでこれらを加算する。また、入力が負数の場合、例えば入力 a が負数の場合 ~a + 1として正数に変換する必要があるが、この+1の加算も上記の加算ステージで行うようにした。
で、固定小数版が浮動小数版に対してどの位誤差があるかだが、以下のようなデータの処理結果で比較してみた。

全データの、RTLでの処理結果とCモデルの処理結果の差の二乗の平方根を合算後、データ数で除して平均誤差を計算した。以下がその結果で、fxp15は15bit版、fxp20が20bit版だ。

平均値でみると20bit版の誤差はそれなりに小さい値だが、最大値は1.8超となっている。ただし、これは単純に回路の値と期待値との差なので、規模感はこれでは判らない。母数(期待値)との比を見るべきなんだろう。

最大誤差の箇所を検索したところ上記の箇所が見つかり、比を計算したところ1.3%の誤差であることが判った。
これ以上bit数を増やしたくないので、う~ん、、、まっいっか。という感じだ。
2013年1月17日木曜日
DFT IPの作成 18
寒い日が続きますなー
風邪をひいてしまったようで、昨日は発熱で寝込んでしまった。。。
今もまだ少し頭がクラクラしている。
固定小数版だが、小数部15bitは精度的に足りないようだ。
画面にスペクトルを表示して鑑賞するだけならこれでもいい気もするが、何か気に入らないのでもう2bit増やして小数部17bitを試してみることにした。
今日は別の話題。
現状のCモデルは複素数は構造体を定義して使っているが、C言語はC99という規格から複素数型が追加になっていてgccも複素数型をサポートしている。Cコンパイラに複素数型があるのに、わざわざ構造体を定義するのも何だし、もしかするとnativeな型を使うと今よりも処理速度が速くなったりするかしら?という興味もあったので実験してみた。また、複素数型を使うと演算式の記述が簡単になるというのも魅力だ。プログラムは以下のように書き換えた。

構造体版と複素数型版での処理時間は以下の通りになった。

意外なことに複素数型の方が5倍も遅い結果となった。ちなみに、gccのバージョンはgcc バージョン 4.6.3 (Ubuntu/Linaro 4.6.3-1ubuntu5)で、OSは64bit版のLinux Mint 13 Mayaだ。そこで、今度は以下のような簡単なプログラムをコンパイルしてどのようなコードが生成されるのかを見てみた。関数f1は複素数型使用版、f2は構造体型使用版だ。

このプログラムをgcc -O2 x.c でコンパイルし、生成された a.out を逆アセンブルしてみた。

これを見ると、f2(構造体型使用版)は関数内に乗算命令(mulss)があるが、f1(複素数型使用版)は__mulcs3というルーチンをコールしている。そしてその__mulcs3は以下のようなコードになっている。

乗算命令の後に何か処理を行っているようだ。gccのソースを確認したところ、このmulcs3はlibgcc2.cの以下の箇所に該当するようだ。

乗算後に無限大や非数等の異常値の判定を行っているようだ。
乗算の度にこれをやっていたら、そりゃ時間かかるわ。
何とか早くする方法は無いのかman gcc等を調べた結果、最適化オプションに-Ofastというオプションがあることが判った。また、-ffast_mathというフラグオプションがあることも判った。
-Ofast オプションでコンパイルすると以下のようになった。また、-O2 -ffast-mathの場合も同等の結果だった。

Cモデルの方も-Ofastオプションを付けてコンパイルし先ほどと同じデータを処理させてみたところ、以下のようになった。

ついでに、プログラムの構造を工夫して、構造体使用版も含めてもっと高速化できないかやってみた。具体的には、三角関数値を1/4象限だけ持ってget_arc関数内で写像してcos, sin値を計算する方式を止めて1周分のテーブルから引くようにし、また、dft_proc内のforループをループ展開するなどした。

その結果、処理速度は以下のようになった。

おっ!、いい勝負だ。構造体版の方が少し速い。
もっと大きいサイズのデータを処理させてみた。

若干だが構造体版の方が速い。その後3回づつ実行した平均値でも比較してみたが、その結果でも構造体版の方が速い結果となった。
以上の結果から、現行の構造体方式でいくことにした。
風邪をひいてしまったようで、昨日は発熱で寝込んでしまった。。。
今もまだ少し頭がクラクラしている。
固定小数版だが、小数部15bitは精度的に足りないようだ。
画面にスペクトルを表示して鑑賞するだけならこれでもいい気もするが、何か気に入らないのでもう2bit増やして小数部17bitを試してみることにした。
今日は別の話題。
現状のCモデルは複素数は構造体を定義して使っているが、C言語はC99という規格から複素数型が追加になっていてgccも複素数型をサポートしている。Cコンパイラに複素数型があるのに、わざわざ構造体を定義するのも何だし、もしかするとnativeな型を使うと今よりも処理速度が速くなったりするかしら?という興味もあったので実験してみた。また、複素数型を使うと演算式の記述が簡単になるというのも魅力だ。プログラムは以下のように書き換えた。

構造体版と複素数型版での処理時間は以下の通りになった。

意外なことに複素数型の方が5倍も遅い結果となった。ちなみに、gccのバージョンはgcc バージョン 4.6.3 (Ubuntu/Linaro 4.6.3-1ubuntu5)で、OSは64bit版のLinux Mint 13 Mayaだ。そこで、今度は以下のような簡単なプログラムをコンパイルしてどのようなコードが生成されるのかを見てみた。関数f1は複素数型使用版、f2は構造体型使用版だ。

このプログラムをgcc -O2 x.c でコンパイルし、生成された a.out を逆アセンブルしてみた。

これを見ると、f2(構造体型使用版)は関数内に乗算命令(mulss)があるが、f1(複素数型使用版)は__mulcs3というルーチンをコールしている。そしてその__mulcs3は以下のようなコードになっている。

乗算命令の後に何か処理を行っているようだ。gccのソースを確認したところ、このmulcs3はlibgcc2.cの以下の箇所に該当するようだ。

乗算後に無限大や非数等の異常値の判定を行っているようだ。
乗算の度にこれをやっていたら、そりゃ時間かかるわ。
何とか早くする方法は無いのかman gcc等を調べた結果、最適化オプションに-Ofastというオプションがあることが判った。また、-ffast_mathというフラグオプションがあることも判った。
-Ofast オプションでコンパイルすると以下のようになった。また、-O2 -ffast-mathの場合も同等の結果だった。

Cモデルの方も-Ofastオプションを付けてコンパイルし先ほどと同じデータを処理させてみたところ、以下のようになった。

ついでに、プログラムの構造を工夫して、構造体使用版も含めてもっと高速化できないかやってみた。具体的には、三角関数値を1/4象限だけ持ってget_arc関数内で写像してcos, sin値を計算する方式を止めて1周分のテーブルから引くようにし、また、dft_proc内のforループをループ展開するなどした。

その結果、処理速度は以下のようになった。

おっ!、いい勝負だ。構造体版の方が少し速い。
もっと大きいサイズのデータを処理させてみた。

若干だが構造体版の方が速い。その後3回づつ実行した平均値でも比較してみたが、その結果でも構造体版の方が速い結果となった。
以上の結果から、現行の構造体方式でいくことにした。
2013年1月8日火曜日
DFT IPの作成 17
バグが取れてちゃんと動作するようになった。次にメモリへの書出し機能を追加する前に、保留にしていた固定小数版に再チャレンジしてみた。固定小数のbit幅は27bitで整数部12bit、小数部15bitとした。また、時間の関係で今日のところはdft演算ループ内のみ、即ち dft_core部のみを固定小数化し、表示用データに加工するdft_power部はそのままとした。そのためdft_coreからdft_powerへの情報はdft_coreの最終段で固定小数を浮動小数に変換して出力するようにしている。

固定小数化の利点は回路規模が小さくなることだ。例えば以下は複素数乗算部(dft_cmply)だが、浮動小数版よりも小さくかつレイテンシーも8から3に減らすことができた。

もっと定量的に比較するために、dft_core部をトップもジュールにして合成してみた。
以下は上段が浮動小数版、下段が固定小数版だ。合成条件は同じだが、クロック周波数等の制約は付けていない。


Spartan3E 250にも入れられるかな??
タイミング制約も付けた全体の合成結果は以下の通り。
最上段がシステムアーキテクチャ、中段が浮動小数版の結果で下段が固定小数版だ。



いつものバイクの通過音を再生させてみた。
見た感じは浮動小数版と変わらない。
どの位差があるのかはシミュレーションして得られたデータとCモデルの出力との平均二乗誤差をとって評価してみるつもりだ。

固定小数化の利点は回路規模が小さくなることだ。例えば以下は複素数乗算部(dft_cmply)だが、浮動小数版よりも小さくかつレイテンシーも8から3に減らすことができた。

もっと定量的に比較するために、dft_core部をトップもジュールにして合成してみた。
以下は上段が浮動小数版、下段が固定小数版だ。合成条件は同じだが、クロック周波数等の制約は付けていない。


Spartan3E 250にも入れられるかな??
タイミング制約も付けた全体の合成結果は以下の通り。
最上段がシステムアーキテクチャ、中段が浮動小数版の結果で下段が固定小数版だ。



いつものバイクの通過音を再生させてみた。
見た感じは浮動小数版と変わらない。
どの位差があるのかはシミュレーションして得られたデータとCモデルの出力との平均二乗誤差をとって評価してみるつもりだ。
2013年1月6日日曜日
2013年1月5日土曜日
DFT IPの作成 15
前回、2048点毎のダンプ値と期待値を比較した結果109番目(ファイル名としては108)から不一致が発生していることが判った。 そこで今度は108 ~ 109間の2048点の演算結果について比較したところ、416番目から不一致になっていることが判った。

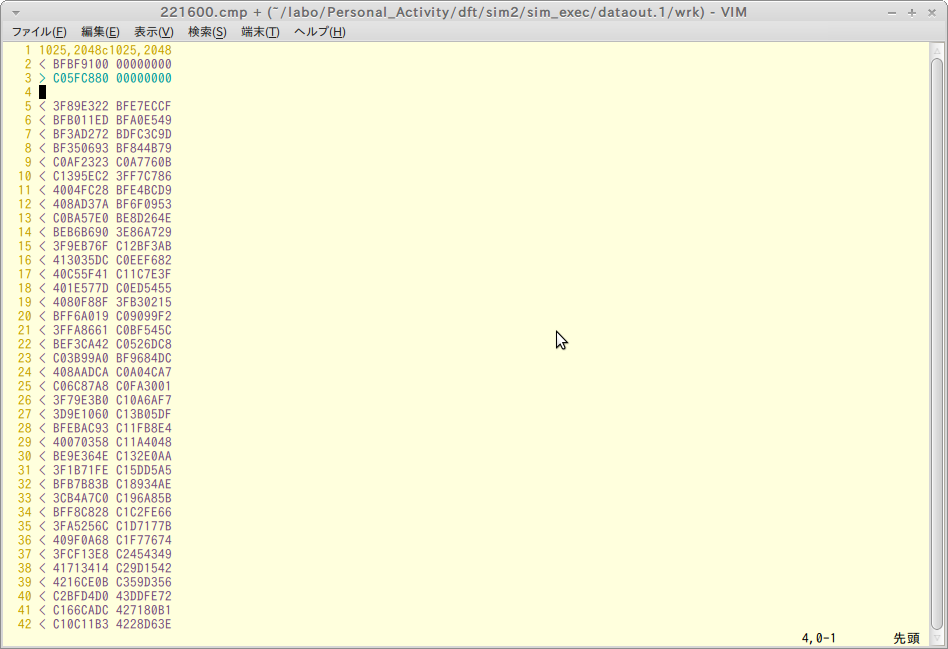
上図の221600.cmpがそれに該当する。(221600/2048 = 108, 221600%2048 =416)
不一致の内容を確認したところ、R側の値が不一致となっていた。以下では図示のために両者の先頭データを並べた。2行目が期待値、3行目がシミュレーション結果だ。

GTKWaveで当該箇所の波形を確認し、それを上流の信号へとたどってみたところ、xd、即ちxp-xp-Nの値に行き着いた。

xdはdft_dline.vというモジュールで計算しているのでその箇所の波形を確認した結果、漸く、不具合箇所が判明した。浮動小数演算器はまったく問題無かった。

不具合の原因はxp-xp-Nのオーバフローだった。これらの値は16bit整数であり、xp-xp-Nの結果は例えば、+32767 - -32768 = 65535となるように結果は17bitとしなければならなかったのに、16bitとしてしまっていた。何という愚かな間違いをしているのかと。→自分
当該箇所を修正し、シミュレーションを再実行し得られた全データについて期待値(Cモデルの出力)と比較したところすべて一致した。
数値演算処理回路を組む場合は、最初にしっかりしたリファレンスモデル(Cモデル)を作成すべきだった。また、不具合がある場合は、まず自分(が作った物)を徹底的に疑うという基本的な事を忘れていた。これは反省すべき点だ。でも、このところ、似たようなIPばかり作っていたので、たまには数値演算処理系のものに挑戦したい思っていたが、それが叶ったし良い勉強になった。ともあれ、不具合箇所を特定し修正できてよかった。

上図の221600.cmpがそれに該当する。(221600/2048 = 108, 221600%2048 =416)
不一致の内容を確認したところ、R側の値が不一致となっていた。以下では図示のために両者の先頭データを並べた。2行目が期待値、3行目がシミュレーション結果だ。
GTKWaveで当該箇所の波形を確認し、それを上流の信号へとたどってみたところ、xd、即ちxp-xp-Nの値に行き着いた。

xdはdft_dline.vというモジュールで計算しているのでその箇所の波形を確認した結果、漸く、不具合箇所が判明した。浮動小数演算器はまったく問題無かった。

不具合の原因はxp-xp-Nのオーバフローだった。これらの値は16bit整数であり、xp-xp-Nの結果は例えば、+32767 - -32768 = 65535となるように結果は17bitとしなければならなかったのに、16bitとしてしまっていた。何という愚かな間違いをしているのかと。→自分
当該箇所を修正し、シミュレーションを再実行し得られた全データについて期待値(Cモデルの出力)と比較したところすべて一致した。
数値演算処理回路を組む場合は、最初にしっかりしたリファレンスモデル(Cモデル)を作成すべきだった。また、不具合がある場合は、まず自分(が作った物)を徹底的に疑うという基本的な事を忘れていた。これは反省すべき点だ。でも、このところ、似たようなIPばかり作っていたので、たまには数値演算処理系のものに挑戦したい思っていたが、それが叶ったし良い勉強になった。ともあれ、不具合箇所を特定し修正できてよかった。
2013年1月2日水曜日
DFT IPの作成 14
波形を4.5秒から以降をダンプするようにしたのだがサイズが33GBとまだまだデカい。
GTKWaveでの操作が重く、作業性が非常に悪い。

そこで、波形ダンプの代わりにアキュムレーションRAMに書き戻すデータをテキストファイルに書き出し、それをCモデルの結果と比較することにした。

出力されたテキストファイルのデータをCモデルの出力形式と同じになるように加工し、pic_gen.cshとavidemuxで動画化してみたところ、不具合の波形が再現された。
このシミュレーションでは浮動小数演算器の部分はVPIタスク化して、CPUによる演算で代用している。それでも異常が出るということは、少なくとも浮動小数演算器の単体動作は問題無いと言えそうだ。次にデータをCモデルの出力とを比較してみたところ109番(ファイル番号は0基点なのでファイル名は108になっている。)以降で不一致が見つかった。

この108のデータについて、シミュレーション出力とCモデルの期待値の差分をグラフ化してみた。

このデータは前半1024点がL側、後半1024点がR側となっている。グラフから後半で不一致が発生している。109以降では以下のように両chで不一致となっていた。

ということで、108周辺に絞って波形ダンプして各部の状態を確認することにした。
GTKWaveでの操作が重く、作業性が非常に悪い。

そこで、波形ダンプの代わりにアキュムレーションRAMに書き戻すデータをテキストファイルに書き出し、それをCモデルの結果と比較することにした。

出力されたテキストファイルのデータをCモデルの出力形式と同じになるように加工し、pic_gen.cshとavidemuxで動画化してみたところ、不具合の波形が再現された。
このシミュレーションでは浮動小数演算器の部分はVPIタスク化して、CPUによる演算で代用している。それでも異常が出るということは、少なくとも浮動小数演算器の単体動作は問題無いと言えそうだ。次にデータをCモデルの出力とを比較してみたところ109番(ファイル番号は0基点なのでファイル名は108になっている。)以降で不一致が見つかった。

この108のデータについて、シミュレーション出力とCモデルの期待値の差分をグラフ化してみた。

このデータは前半1024点がL側、後半1024点がR側となっている。グラフから後半で不一致が発生している。109以降では以下のように両chで不一致となっていた。

ということで、108周辺に絞って波形ダンプして各部の状態を確認することにした。
登録:
コメント (Atom)
ERROR: Failed to spawn fakeroot worker to run ...
なにかと忙しくてなかなか趣味の時間を確保できない。 ...orz 家の開発機のOSはLinux Mintなのだが、最近バージョンを22に更新したところ、myCNC用のpetalinuxをビルドできなくなってしまった。ビルドの途中で ERROR: Failed to spawn ...

-
 FT232RというUSB-UART変換ICがある。このICにはBit Bang Modeという機能があって、UART用の端子がGPIO的制御が可能になる。 FT232Rを搭載したUSB-UART変換基板は秋月電子やマルツパーツ等色んなところで売られていて私もSparkfunのF...
FT232RというUSB-UART変換ICがある。このICにはBit Bang Modeという機能があって、UART用の端子がGPIO的制御が可能になる。 FT232Rを搭載したUSB-UART変換基板は秋月電子やマルツパーツ等色んなところで売られていて私もSparkfunのF... -
 zumi32を下図の様な構成にし、simulationで粗動作確認を始めた。 programは下図の様に機能検査を行い結果が正常なら次の検査へ分岐する。 結果が期待通りでなければ、HALT命令を実行して停止する。 上図の部分の波形は以下のようになる。 ib_ren...
zumi32を下図の様な構成にし、simulationで粗動作確認を始めた。 programは下図の様に機能検査を行い結果が正常なら次の検査へ分岐する。 結果が期待通りでなければ、HALT命令を実行して停止する。 上図の部分の波形は以下のようになる。 ib_ren...