
XO2用に合成した場合はモジュール階層がある程度維持されるようで、canモジュールも各サブモジュールの信号名も保持されたネットリストになっており、can_rxpp(受信モジュール)のステートマシンのステートカウンタの信号も残っていたのでその信号を見てみたところ、上図のようになっていた。 stateがステートカウンタ、prv_stateは直前のステート値を保持するレジスタである。
このステートマシンはステート数16で4bitのステートカウンタの全ての値に意味がある。従って、state[1]が z になるのは変だ。 この z という状態はネットが浮いている、つまりどこにも接続されていないということなので、合成エンジンはstate[1]を不要と判断してその部分のレジスタを削除した可能性がある。

一方のprv_stateは一つ前のstateの値を保持するレジスタで、

prv_stateの値は以下の2箇所(794行目と821行目)で参照されている。

ST_ERROR値は4'd12とST_OVLDの値は4'd14なので、論理式の部分を解くと以下のようになり、確かにprv_state[1]は削除できることが解る。 ( prv_state != ST_ERROR && prv_state != ST_OVLDは、prv_state == ST_ERROR || prv_state == ST_OVLD の反転値なので両者でprv_state[1]は不要である。)

prv_stateの結果は間違っていないがstateの合成結果は明らかに間違っている。合成の最適化オプションの設定が関係しているかも知れない。上記合成は以下の最適化オプション設定で行った。
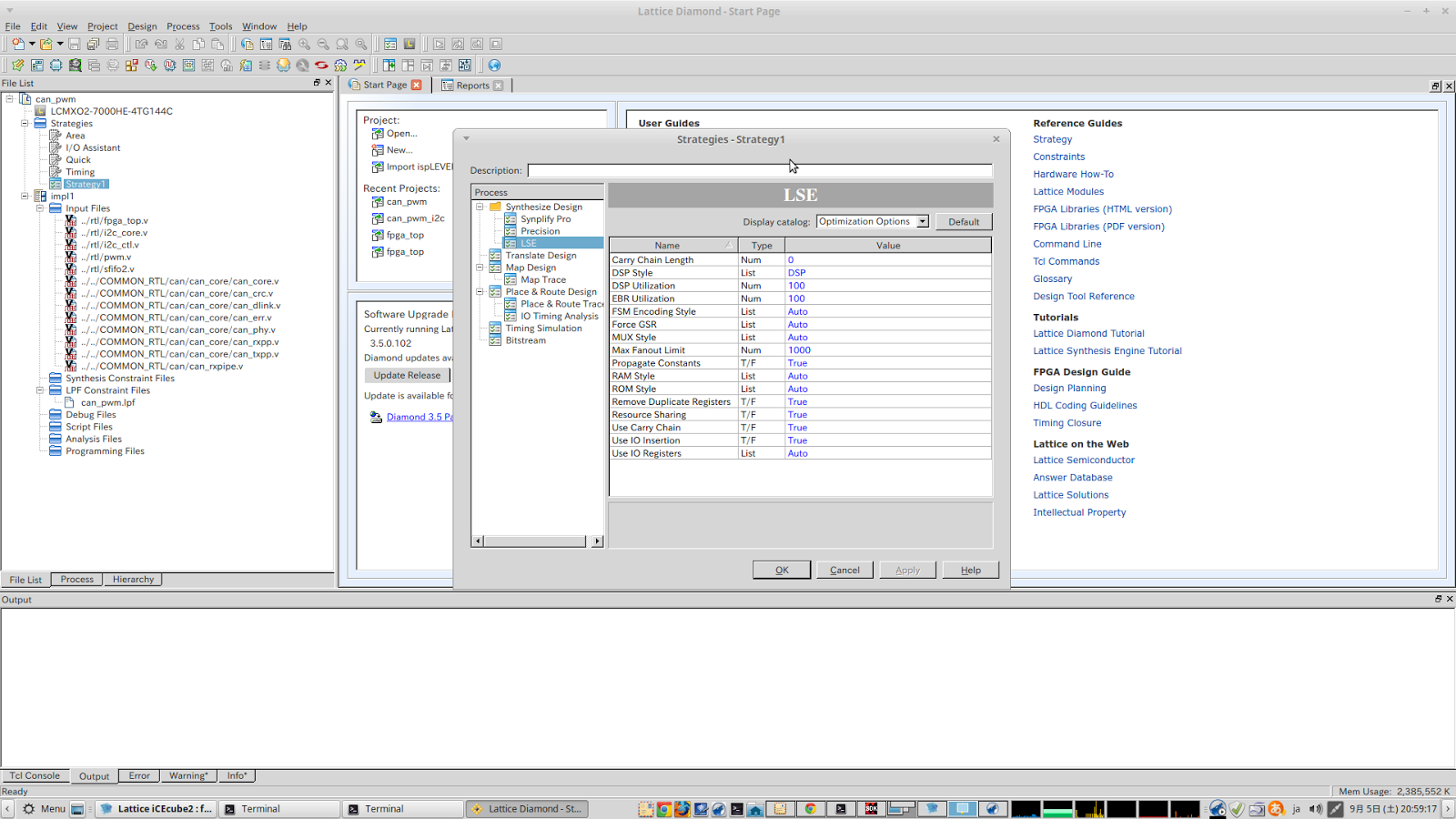
そこで、最適化オプションのResource SharingをFalseにして合成しなおしてみた。(尚、iCE40用のLSEの設定ではResoure SharingはデフォルトでTrueとなっている。)

生成されたネットリストでシミュレーションしてみると・・・

旨く行った! state[1]も正常だ。
この結果を受けて、iCEcube2でもResource SharingをFalseにして合成してみた。

生成されたネットリストでシミュレーションしてみると・・・

こちらも旨く行った! iCE40用の合成の場合は階層情報が維持されないようで、can_rxppモジュールのstateやprv_state等も上記の信号名しか参照できなかった。が、canはACKフレームを出しているので期待通りの動作をしている。
上述の通り、can_rxppモジュールのステートマシンはステート数が16あるステートマシンだ。

ステート間の遷移パターンは49パターンある。

上図のcovered_fsm、... はCoveredというコードカバレッジツール用のもので、このステートマシンの(記述されている)ステート遷移がシミュレーションで全てカバーされているか(検証されているか)を見るための記述である。 このcan_ip開発時に検証した。(CAN IPのDEBUG 8)
上記のような複雑なステートマシンの場合は、Resource Sharingは旨く作用しない場合があるのかも知れない。 ということで、Synplifyで旨く行って、LSEで旨く行かないことの原因らしきものは判った。
次は、実機でFPGAが反応しない(ACK応答しない)件だ。
Resource SharingをFalseにして合成したビットマップファイルをFPGAにダウンロードして実機で動作させてみたところ、Synplifyの場合と同じでACKフレームが出ない。反応していないように見えた。 そこで、can_ipの内部信号をFPGAの未使用ピンに出して、その状態をロジアナで観測してみた。

引き出したのはステートマシンがIDLEステートにいることを示す信号と、ERRORステートにいることを示す信号、そして、can_phyモジュールで生成されるcanのRXD信号をサンプリングするためのイネーブル信号(b2r_spen)だ。



引き出したのはステートマシンがIDLEステートにいることを示す信号と、ERRORステートにいることを示す信号、そして、can_phyモジュールで生成されるcanのRXD信号をサンプリングするためのイネーブル信号(b2r_spen)だ。


その結果、ステートマシンは動いてはいるようだが途中でエラーステートに遷移していることが判った。 さらに細かく見ていくと、b2r_spenの間隔が異常に短い箇所があることが判った。

b2r_spenはcan_phyモジュールで生成されていて、信号受信が無い(RXD信号が変化しない)場合は、自走してビットレートに応じた周期のパルスになる。今の場合は1Mbpsなので1us周期のパルスとなる。また、RXD信号に0➔1または1➔0の遷移がある場合は、そのエッジで周期が微調整される。その様子は以前CAN IPのDEBUG 7に書いた。
俯瞰して見てみると、この現象には周期性があるようだ。

なので、ノイズでの誤動作とかメタステーブルとかが原因では無さそうだ。
念の為オシロスコープでも見てみた。

そこで、ロジアナで採取したCANのRXD信号をテストベンチに取り込んで、シミュレーションで再現するかを見てみることにした。その為には・・・
まず、GTKWaveで観測している波形をTIMファイルにエクスポートする。

TIMファイルは以下のような形式のテキストファイルで全ての信号の情報を含んでいるので、そこからRXDの部分を抽出する。


そして、時刻情報と信号の値をテキストエディタなどを使ってテストベクタに変換する。

このベクタでRTLシミュレーションを実施したところ、現象が再現された。

色々原因を探った結果、Zynq側のビットレートが1Mbpsに対して9%程度低い可能性が見えてきた。
以下の波形はRXD信号に変化が無くてcan_phyが自走してb2r_spenを生成している部分だが、パルス間隔は1us (=1Mbps)となっていて正しい。


これに対して、RXDを見てみると、以下の波形は9シンボル分の間隔を見ているが、その値は9.83usとなっている。 9.83÷9 ≒ 1.09なので9%程度ビットレートがズレている。
CANの規格では送受信間のクロックのズレは最大1.58%となっているので9%は大きすぎる。

Zynq側に何か問題がありそうだ。
ZynqのCANモジュールのリファレンスクロックは24MHzだが、IO_PLLのから供給していて実際は23.809525MHzが供給されている。

ただ、誤差は0.8%程度なのでこれが原因とは考えにくい。とすると、CANモジュール内部のクロック関係の設定が怪しい。クロック関連の設定要素としてはBRPR(プリスケーラ)レジスタとBTRレジスタがある。それぞれの設定とビットレートとの関係はZynq-7000 AP SoC Technical Reference Manualに書いてある。現在のプログラムの設定値もここを参考にして決定した。

が、よく見ると、最下段のfreqBIT_RATEの式は間違っているようだ。Sync Segmentの分が含まれていない。正しくは、
freqBIT_RATE = freqCAN_REF_CLK / ((can.BRPR[BRP] + 1) * (3 + can.BTR[TS1] + can.BTR[TS2]))
でなければならない筈だ。現在の設定値はBRPR[BRP]が1,BTR[TS1]が8、BTR[TS2]が2なので、間違っている方の式でビットレートを求めると、24/((1+1)×(2+8+2)) = 1と1Mbpsになるが、正しくは、24/((1+1)×(3+8+2)) ≒ 0.923の筈で、これは1/0.923 = 1.083なので8%程度の誤差となる。
原因はここのようだ。
そこで、プログラムのTS1の値を7に変更することにした。

修正したプログラムを走らせてみたところ、旨くいった!! やたっ!
以下のプログラムではPWMのDutyを0%から100%まで5%刻みでCANバス経由で設定しているが、そのとおりにPWMの出力は変化している。



ということで、遂に世界最小クラスかもしれないFPGAボードでCANを動かすことが出来た。!!
やったー \(^_^)/
iCE40LMのパッケージへのハンダ付けの挑戦をするためにデジタル温調ハンダゴテを購入したのが2月だから、ここまで来るのに8ヶ月位かかったが、なんとかCANの動作まで漕ぎ着けた。 また、今回は2Gsのオシロよりも100Msの自作ロジアナの方が役に立った。このロジアナは作ってよかったと実感している。自作したものが十分使えて役に立ったという点も非常にうれしい。
次はCANバス経由でのリードバックを確認しよう。


